软件设计笔记
目录
二进制码
原码
正整数转原码 = 直接求二进制,高位置0
负整数转原码 = 直接求二进制,高位置1
| 示例 | 符号位 | 值 | 原码(结果) |
|---|---|---|---|
| 计算 (1)原 | 0 |
000'0001 |
0'000'0001 |
| 计算 (-1)原 | 1 |
000'0001 |
1'000'0001 |
| 计算 (127)原 | 0 |
111'1111 |
0'111'1111 |
| 计算 (-127)原 | 1 |
111'1111 |
1'111'1111 |
纯小数转原码 = 乘2取整,顺序排列
计算 (0.8125)原:
| 乘2 | 结果 | 取整(顺序排列) |
|---|---|---|
| 0.8125 x2 | 1.625 | 1 |
| 0.625 x2 | 1.25 | 1 |
| 0.25 x2 | 0.50 | 0 |
| 0.50 x2 | 1.00 | 1,小数部分为0,停止计算 |
于是,(0.8125)原 = 0♢110'1000
同理,(-0.8125)原 = 1♢110'1000
计算 (0.46)原:
| 乘2 | 结果 | 取整(顺序排列) |
|---|---|---|
| 0.46 x2 | 0.92 | 0 |
| 0.92 x2 | 1.84 | 1 |
| 0.84 x2 | 1.68 | 1 |
| 0.68 x2 | 1.36 | 1 |
| 0.36 x2 | 0.72 | 0 |
| 0.72 x2 | 1.44 | 1 |
| 0.44 x2 | 0.88 | 0 |
| 0.88 x2 | 1.76 | 1,但是除去符号位只能有7位,所以这里开始要削掉 |
于是,(0.46)原 = 0♢011'1010
同理,(-0.46)原 = 1♢011'1010
反码
反码正数 = 原码
反码负数 = 符号不变,原数取绝对值,然后求原码,再求反(0置1,1置0)
| 示例 | 绝对值原码 | 反码(结果) |
|---|---|---|
| 计算 (1)反 | 0'000'0001 |
0'000'0001 |
| 计算 (-1)反 | 1'000'0001 |
1'111'1110 |
| 计算 (127)反 | 0'111'1111 |
0'111'1111 |
| 计算 (-127)反 | 1'111'1111 |
1'000'0000 |
| 计算 (0.8125)反 | 0♢011'0100 |
0♢011'0100 |
| 计算 (-0.8125)反 | 1♢011'0100 |
1♢100'1011 |
补码
补码正数 = 反码 = 原码
补码负数 = 符号不变,反码末尾 + 1
| 示例 | 绝对值原码 | 反码 | 补码(结果) |
|---|---|---|---|
| 计算 (1)补 | 0'000'0001 |
0'000'0001 |
0'000'0001 |
| 计算 (-1)补 | 1'000'0001 |
1'111'1110 |
1'111'1111 |
| 计算 (127)补 | 0'111'1111 |
0'111'1111 |
0'111'1111 |
| 计算 (-127)补 | 1'111'1111 |
1'000'0000 |
1'000'0001 |
| 计算 (0.8125)补 | 0♢011'0100 |
0♢011'0100 |
0♢011'0100 |
| 计算 (-0.8125)补 | 1♢011'0100 |
1♢100'1011 |
1♢100'1100 |
移码
移码 = <符号位取反> + 补码值
| 示例 | 绝对值原码 | 反码 | 补码 | 移码(结果) |
|---|---|---|---|---|
| 计算 (1)补 | 0'000'0001 |
0'000'0001 |
0'000'0001 |
1'000'0001 |
| 计算 (-1)补 | 1'000'0001 |
1'111'1110 |
1'111'1111 |
0'111'1111 |
| 计算 (127)补 | 0'111'1111 |
0'111'1111 |
0'111'1111 |
1'111'1111 |
| 计算 (-127)补 | 1'111'1111 |
1'000'0000 |
1'000'0001 |
0'000'0001 |
| 计算 (0.8125)补 | 0♢011'0100 |
0♢011'0100 |
0♢011'0100 |
1♢011'0100 |
| 计算 (-0.8125)补 | 1♢011'0100 |
1♢100'1011 |
1♢100'1100 |
0♢100'1100 |
小数的二进制
整数和小数分开算,再拼接。
整数 176 求得二进制 1011'0000
小数 0.0625 用 乘2取整 方法求得二进制 0001'0000
拼接结果: 1011'0000.0001'0000
浮点数
小数点移位
类似科学记数法的表示形式
对于二进制小数 1011'0000.0001'0000(真值176.0625),有很多种表示方式:
-
10110000.00010000× 2⁰ -
1011000.000010000× 2¹ -
101100.0000010000× 2²
浮点数规格化与运算
规格化表示要求将尾数的绝对值限定在区间 [0.5, 1)
浮点数补码规格化
正浮点数补码规格化: 小数点移位,直到尾数符合 0.1XX'XXXX 格式。
负浮点数补码规格化: 小数点移位,直到尾数符合 1.0XX'XXXX 格式。
IEEE 754标准
IEEE 浮点数的格式:
<符号位> <阶码的移码表示> <尾数的原码表示>
小数点移位,直到尾数符合 1.XXX'XXXX 格式,此时获得指数n (示例: 1.XXX × 2ⁿ)。然后移除最高位,变成 .XXX'XXXX,再移除小数点。这个最高位称 隐含位,最后按单双精度的尾数长度补0。
由于 IEEE 定义阶码不能有符号,则 阶码 = 指数n + 127,转为二进制即得阶码移码。
| 步骤 | 说明 |
|---|---|
| 真值 | 176.0625 |
| 计算原码 | 10110000.00010000 |
| 规格化: 移位 | 1.011000000010000 × 2⁷ |
| 规格化: 求得阶码 | 指数: 7,阶码: (127 + 7 = 134)₁₀,阶码移码: (1000'0110)₂ |
| 规格化: 获得尾数 | 1.011000000010000 |
| 规格化: 尾数去隐含位 | 尾数 = .011000000010000 |
| 规格化: 尾数补齐长度 | 尾数23位,补0 = 0110'0000'0010'0000'0000'000 |
| 规格化: 结果格式 | <符号> <阶码> <尾数> |
| 结果 | 0 10000110 01100000001000000000000 |
浮点数相加运算
- 对阶,小阶看齐大阶,尾数右移
- 尾数相加运算
校验码
奇偶校验
奇偶校验就是看编码中有奇数个或偶数个相同的码。
0100'1101 有4个1,为偶数,但是要求奇校验,所以在末尾加多个 1。
变成 0100'1101'1,为 5个1,奇数,即结果。
偶校验同理。
奇偶校验查不出奇数或偶数个错误。
海明码
海明码是嵌在编码中的校验码,原编码叫 信息码。
海明码中,设校验码数量为 k,则 2ᵏ - 1 >= 整条编码的数量(信息码数+校验码数)。
以公式显示:
设校验码数量为 k,信息码数为 n,则:
2ᵏ - 1 >= n + k
原编码 0110'1001,长度 8。需要 4 位校验码,则总长 12。
设信息码为 D(n)
| D7 | D6 | D5 | D4 | D3 | D2 | D1 | D0 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
校验码的位置 P(n)
4位校验码放置的位置(高位到低位):
P0 = 2⁰ = 1
P1 = 2¹ = 2
P2 = 2² = 4
P3 = 2³ = 8
信息码校验码合起来
| 地址 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D(n) | D7 | D6 | D5 | D4 | D3 | D2 | D1 | D0 | ||||
| P(n) | P3 | P2 | P1 | P0 | ||||||||
| D(n)值 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | ||||
| P(n)值 | ? | ? | ? | ? |
用校验码的地址凑信息码的地址
| 信息码 | 地址 | 校验码组成 |
|---|---|---|
| D7 | 12 | P3(8) + P2(4) |
| D6 | 11 | P3(8) + P1(2) + P0(1) |
| D5 | 10 | P3(8) + P1(2) |
| D4 | 9 | P3(8) + P0(1) |
| D3 | 7 | P2(4) + P1(2) + P0(1) |
| D2 | 6 | P2(4) + P1(2) |
| D1 | 5 | P2(4) + P0(1) |
| D0 | 3 | P1(2) + P0(1) |
按上表算出校验码与哪些信息码关联
| 校验码 P(n) | 关联的信息码值相加 | 结果 |
|---|---|---|
| P0 | D0 + D1 + D3 + D4 + D6 | 1 + 0 + 1 + 0 + 1 = 1 |
| P1 | D0 + D2 + D3 + D5 + D6 | 1 + 0 + 1 + 1 + 1 = 0 |
| P2 | D1 + D2 + D3 + D7 | 0 + 0 + 1 + 0 = 1 |
| P3 | D4 + D5 + D6 + D7 | 0 + 1 + 1 + 0 = 0 |
完善表格,算出结果
| 地址 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D(n) | D7 | D6 | D5 | D4 | D3 | D2 | D1 | D0 | ||||
| P(n) | P3 | P2 | P1 | P0 | ||||||||
| D(n)值 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | ||||
| P(n)值 | 0 | 1 | 0 | 1 | ||||||||
| 最终结果 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
0110'0100'1101
码距
码距即两个编码之间,相同位翻转的次数。
-
Example1: A =
1100, B =1101, 码距 = 1, 只有最低位翻转了。 -
Example2: A =
1001, B =0010, 码距 = 3。
海明码最小距离为 3,并可以纠错。
CRC循环冗余校验码的码距一直是 1,但只能找错,不能纠错。
逻辑运算
或(∨,+)
只要有一个变量是1,则结果为1。
| 逻辑符 | 伪代码 | C程序 |
|---|---|---|
A ∨ B |
A or B |
`A |
0+0=0 0∨0=00+1=1 0∨1=11+0=1 1∨0=11+1=1 1∨1=1
与(∧,×)
只要有一个变量是0,则结果为0。
| 逻辑符 | 伪代码 | C程序 |
|---|---|---|
A ∧ B , AB |
A and B |
A & B |
0×1=0 0∧1=01×0=0 1∧0=01×1=1 1∧1=1
非(¯,顶横线)
求反
| 逻辑符 | 伪代码 | C程序 |
|---|---|---|
Ā |
not A |
!A |
异或(⊕,⊻)
两个变量值相同时为0,否则为1。
| 逻辑符 | 伪代码 | C程序 |
|---|---|---|
Ā |
A xor B |
A ^ B |
可靠度
串联系统
| –> | R₁ | R₂ | R₃ | … | Rn | –> |
可靠度 = R₁ × R₂ × … × Rn
并联系统
| R₁ | ||
| R₂ | ||
| –> | R₃ | –> |
| … | ||
| Rn |
可靠度 = 1 - ((1 - R₁) × (1 - R₂) × … × (1 - Rn))
CPU
CPU 是计算机的控制中心。
CPU 的组成
- 运算器
- 寄存器
- 内部总线
- 控制器
- 程序计数器(PC),总是存放下一条指令的地址
- 指令寄存器,存储运算结果
- 指令译码器
- 时序产生器
- 操作控制器
指令集
| CISC | RISC |
|---|---|
| - 增强原有指令的功能 - 用新指令取代软件完成的功能 |
- 采用硬布线逻辑执行指令 - 指令种类、寻址方式更少 |
运算速度
-
CPI 每条指令需要的时钟周期
-
MIPS 每秒处理多少百万条指令
-
主频 每秒振多少次
MIPS = 主频 / (CPI × 10⁶)
磁盘容量计算
盘片
盘片有正反2个记录面。在多个盘片组成的硬盘中,一般最外层2个记录面不记录数据。
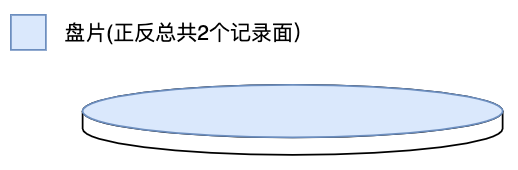
| 记录面 | 一般情况下,记录面 = (盘片数 × 2) - 2 (盘片正反2面 - 外层2面) |
磁道
盘片上的多个同心圆为磁道。
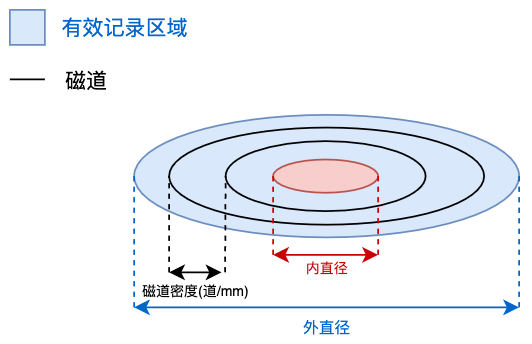
| 单面磁道数 | (外半径 - 内半径) × 磁道密度 |
记录位
磁道上有很多凹凸不平的记录位,表示0和1。
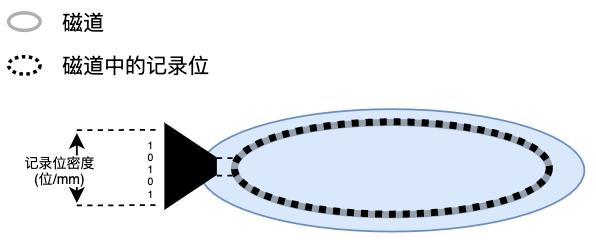
非格式化容量
| 磁道容量(单个记录面) | 记录位密度 × 内圈周长 外圈记录位密度受制于内圈的密度,故以内圈为基准 |
| 非格式化容量(单个记录面) | 磁道数 × 磁道容量 |
扇区
格式化后,将磁道分成很多个扇形,扇形与磁道的重合部分为扇区。
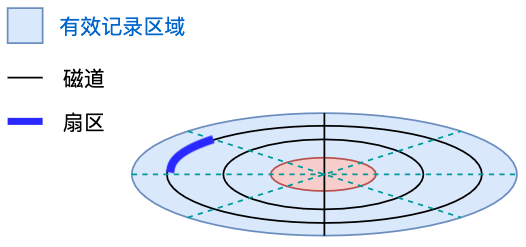
格式化容量
| 某磁道格式化容量 | 该磁道扇区数 × 每个扇区容量 |
| 格式化容量(单个记录面) | 扇区数 × 每个扇区容量 × 磁道数 |
顺序磁盘读记录和处理问题
假设某磁盘的每个磁道划分成9个物理块,每块存放1个逻辑记录。逻辑记录 R0,R1,…,R8 存放在同一磁道上,记录安排顺序如下表所示:
| 物理块 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 逻辑记录 | R0 | R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 |
如果磁盘的旋转速度为 27ms/周,磁头当前处在 R0 的开始处。若系统顺序处理这些记录,使用单缓冲区,每个记录处理时间为 3ms,则处理这9个记录的最长时间为?
每个记录读取时间 = 27(ms/周) / 9(个记录) = 3(ms/记录)
每个记录处理时间 = 3ms
从物理块1(R0)开始:
-
经过3ms,读完块1,磁头到达块2起始
-
经过3ms,处理完块1,磁头到达块3起始
按上面的顺序,现在要读块2,但是磁头在块3,所以磁头要转大约一圈,让磁头到达块2的起始处,读块2。
- 经过 27ms - 3ms = 24ms,磁头到达块2起始
- 经过 3ms,读完块2,磁头到达块3起始
- 经过 3ms,处理完块2,磁头到达块4起始
按上面的顺序,现在要读块3,但是磁头在块4起始,所以磁头要再转大约一圈,让磁头到达块3的起始处,读块3。
- 经过 27ms - 3ms = 24ms,磁头到达块3起始
- 经过 3ms,读完块3,磁头到达块4起始
- 经过 3ms,处理完块3,磁头到达块5起始
找到规律,从块2开始,每次读+处理前都要等 24ms 磁头转一圈。
直到要读块9,磁头在块1起始,所以仍然要让磁头继续转大约一圈,让磁头到达块9起始。
| 物理块 | 记录 | 耗时 |
|---|---|---|
| 1 | R0 | 3ms读 + 3ms处理 |
| 2 | R1 | 24ms等 + 3ms读 + 3ms处理 |
| 3 | R2 | 24ms等 + 3ms读 + 3ms处理 |
| 4 | R3 | 24ms等 + 3ms读 + 3ms处理 |
| 5 | R4 | 24ms等 + 3ms读 + 3ms处理 |
| 6 | R5 | 24ms等 + 3ms读 + 3ms处理 |
| 7 | R6 | 24ms等 + 3ms读 + 3ms处理 |
| 8 | R7 | 24ms等 + 3ms读 + 3ms处理 |
| 9 | R8 | 24ms等 + 3ms读 + 3ms处理 |
全加上来,总耗时 246ms。
指令-流水线-吞吐率
流水线时间 = (一条指令所需时间) + (n条指令 - 1) × 最长一段所需时间
吞吐率 = n条指令 ÷ 流水线时间
进程管理
PV 操作
| P (S) | 申请一个 S 资源,S--,如果资源不足则等待 |
| V (S) | 释放一个 S 资源,S++,如果此时S=0则唤醒一个等待中的进程 |
多媒体
位元与颜色数
如果一幅图像深度为 b 位,则该图像的最多颜色树或灰度级位 2ᵇ 种。
例1: 单色图像每个像素有 8 位,则最大灰度数为 2⁸ = 256
例2: 一幅彩色图像用分量 R、G、B 表示,若 3 个分量的像素位分别是 4、4、2,则最大颜色数为 2⁴⁺⁴⁺² = 2¹⁰ = 1024
MPEG
| 用途 | 标准 |
|---|---|
| CD 编码 | MPEG-1 |
| VCD 编码 | MPEG-2 |
| H.264 编码 | MPEG-4 |
| 仅内容描述接口 | MPEG-7 |

常用媒体对应标准图 引用自Wikipedia
防火墙
| 包过滤防火墙 | - 源IP地址 - 源端口号 - 目标IP地址 - 目标端口号 |
数字证书
数字证书由 CA 发行,包含 版本、序列号、签名算法标识、签发人、有效期、主体名、主体公钥,附有 CA 签名。
| 验证网站真伪 | 验证网站证书中 CA的签名 |
| 与网站通信 | 用网站证书的公钥加密 |
| 网站收到消息 | 用网站的私钥解密 |
计算机病毒
以感染途径、技术区分
| 病毒类型 | 动机 | 识别 |
|---|---|---|
| 文件型 | 感染可执行文件(EXE,COM等) | - |
| 引导型 | 影响软盘、硬盘、引导扇区 | - |
| 目录型 | 修改硬盘上所有文件的地址 | - |
| 宏病毒(Macro) | 感染WORD、EXCEL文档 | 文件名前缀 Macro |
RUP-统一软件开发过程
开发过程描述
| 谁做 | 角色 |
| 做什么 | 制品 |
| 怎么做 | 活动 |
| 什么时候做 | 工作流 |
阶段
| 初启阶段 | [案例评估] 目标: 系统建立商业案例和确定项目的边界 里程碑: 生命周期目标 产出: 早期风险评估、项目计划 |
| 精化阶段 | [制定计划] 目标: 分析问题领域,建立健全的体系结构基础,编制项目计划,淘汰项目中最高风险的元素 里程碑: 生命周期的架构 产出: 补充过的需求分析、原型等制品 |
| 构建阶段 | [开发测试] 目标: 完成分析、设计、开发、测试工作 里程碑: 初始运维功能 产出: 准备交付给最终用户的产品 |
| 交付阶段 | [产品交付] 目标: 将软件产品交付给用户群体 里程碑: 产品发布 产出: 交付给用户产品发布版本 |
风险评估
- 风险识别: 试图系统化地确定项目计划的威胁(估算、进度、资源分配)
- 风险预测: 又称风险估算,从2个方面评估风险[风险发生的概率]、[风险发生产生的后果]
- 风险评估: 根据风险发生的概率和产生的影响预测是否影响参考水平值
- 风险控制: 辅助项目建立处理风险的策略(风险避免、风险监控、风险管理、意外事件计划)
项目计划
关键路径
关键路径 = 耗时最长的那条 = 完成项目最短时间
某任务总时差 = 最迟开始时间 = (关键路径 - 该任务开始到终点的每一条路径),找出最小值即总时差
Gantt、PERT
Gantt 以日历为基准描述项目任务,可以清楚看到任务的持续时间和并行,但是不能描述任务之间的依赖关系。
PERT 图可以明确表达任务的依赖关系,和整个工程的关键路径,但是看不到任务并行情况。
程序编译
编译过程
- 词法分析: 扫描源程序的字符流,然后识别出单词和符号。
- 语法分析: 将单词序列组合成语法短语,判断源程序的结构是否正确,源程序的结构由上下文无关文法描述
- 语义分析: 类型检查
- 中间代码生成
- 代码优化
- 目标代码生成
形参实参
void add (int i) |
i 是形参 |
add(5) |
5 是实参 |
实参将值传递给形参。
冗余技术
- 结构冗余: 静态、动态、混合冗余
- 信息冗余: 检测或纠正信息在运算或传输中的错误另外加的信息
- 时间冗余: 重复执行指令消除瞬时错误带来的影响
- 冗余附加技术: 实现上述冗余技术所需的资源和技术
软件成熟度模型(CMM)
| 核心 | 特点 | |
|---|---|---|
| 1.初始级 | - | 没有健全的管理制度 |
| 2.可重复级 | [建立制度] 建立基本的项目管理和实践来跟踪项目费用、进度和功能特性 | 建立基本的项目管理 |
| 3.已定义级 | [标准化] 使用标准开发过程(或方法论)构建(或集成)系统 | 开发过程标准化,完善的培训和专家评审制度 |
| 4.已管理级 | [管理质量] 管理层寻求更主动地应对系统的开发问题 | 产品和过程已建立了定量的质量目标 |
| 5.已管理级 | [改进] 连续地监督和改进标准化的系统开发过程 | 可集中精力改进过程,采用新技术、新方法 |
ISO/IEC 9126 质量模型
| 功能性 | 适合性 准确性 互操作性 保密安全性 功能性 依从性 |
| 可靠性 | 成熟性 容错性 易恢复性 可靠性 依从性 |
| 易用性 | 易理解性 易学性 易操作性 吸引性 易用性 依从性 |
| 效率 | 时间特性 资源利用 依从性 |
| 软件维护性 | 易分析性 易改变性 稳定性 易测试性 依从性 |
| 可移植 | 适应性 易安装性 共存性 易替换性 依从性 |
项目配置
软件配置的活动
- 变更标识
- 变更控制
- 版本控制
三库管理
- 开发库: 开发人员的工作空间
- 受控库: 保存已批准的配置项,由配置管理员管理与维护
- 产品库: 最终产品存放的位置,等待交付客户使用
软件测试
- 单元测试(最小模块测试)
- 集成测试
- 自顶向下即成(先集成主模块,按层次结构向下集成)
- 自底向上集成(先从原子模块测试)
- 发现模块之间协作的问题,专测模块传参错误
- 冒烟测试(每个版本在正式测试前做一次简单的验证性测试,确保新代码按预期执行)
- 系统测试(在系统实际环境中测试)
- 回归测试(修改了旧代码后,重复以前的测试,确认修改后的代码没有引入新的错误)
- 验收测试
- Alpha 测试 (内测)
- Beta 测试 (公测)
- Gamma 测试 (正式发行的候选版)
程序控制流
分支覆盖法
即找出所有到达最终结果的程序路径。
软件复杂性度量
- 规模: 指令数、代码行数
- 难度: 程序出现的操作数
- 结构: 程序结构有关的度量表示
- 智能度: 算法的难易
McCabe 复杂性度量法
设 m 为有向弧数(箭头),n 为节点数(几何形状)
复杂度 = V(g) = m - n + 2
软件维护
| 准确性 | 修复系统开发阶段出现错误,但是测试阶段未发现的错误 |
| 改正性维护 | 发现bug并修复 |
| 适应性维护 | 根据系统、市场环境变化而修改 |
| 完善性维护 | 用户提出新需求而修改 |
| 预防性维护 | 主动修改 |
极限编程
价值观
- 沟通
- 简单性(朴素)
- 反馈
- 勇气
原则
- 快速反馈
- 假设简单
- 增量变化
- 拥抱变化
- 高质量工作
实践
- 计划游戏: 快速制定计划、随着细节不断变化而完善
- 小型发布: 尽可能早交付
- 隐喻: 找到合适的比喻传达信息
- 简单设计: 只处理当前的需求使设计保持简单
- 测试先行: 先写测试代码再写程序
- 重构: 重新审视需求和设计,重新描述
- 结队编程
- 集体代码所有制
- 持续集成: 按日甚至按小时为客户提供可执行版本
- 每周工作40小时
- 现场客户
- 编码标准
面向对象
开发方法
- Booch
- Coad/Yourdon
- OMT (Object Model Technology,对象建模技术)
- OOSE (Object-Oriented Software Engineering,面向对象软件工程)
- UML (Booch, OMT, OOSE 的统一)
开发过程
面向对象分析
为了获得对应用问题的理解,主要任务是抽取和整理用户需求并建立问题域精确模型。
活动: 认定对象、组织对象、描述对象之间相互作用、定义对象操作、定义对象内部信息
面向对象设计
采用协作的对象、对象的属性和方法说明软件的解决方案的一种方式。
强调的是定义软件对象和这些对象如何协作来满足希求,延续了面向对象分析。
面向对象实现
强调采用面向对象程序设计语言实现系统。
面向对象测试
根据规范说明来验证系统设计的正确性。
实体类、边界类、控制类
| 实体类 | 核心类,数据和业务逻辑 | e.g. 持卡人类,支付、修改密码等业务行为 |
| 边界类 | 和用户交互,内外系统联系媒介 | e.g. 命令行渲染类和web渲染类 |
| 控制类 | 协调实体类和边界类交互 | e.g. MVC中的控制器类 |
类间关系
| 依赖 | e.g. A 在方法中临时引用了 B |
| 关联 | e.g. A 的成员变量引用了 B |
| 聚合 | 整体与部分的关系,但是失去了该部分仍能工作,e.g. 汽车与车载FM |
| 组合 | 整体与部分的关系,但是失去了该部分不能工作,e.g. 汽车与轮子 |
| 继承 | 常用且明显的继承关系 |
正规式
自动机
自动机识别的方式,传入字符串,从初态开始识别,逐个字符识别。
数据模型
| 层次模型 | [倒过来的树状] 用树状结构组织数据 |
| 网状模型 | [网状] 用有向图表示实体和实体之间的联系 |
| 关系模型 | [二维表] 使用表格表示实体和实体之间关系 |
数据库
范式
1NF
要求: 每一个分量必须是不可分的数据项。
2NF
要求: 基于1NF,每一个非主属性完全函数依赖于码。
3NF
要求: 基于2NF,每一个非主属性既不部分依赖于码也不传递依赖于码。
关系代数
笛卡尔积(×)
相当于 SQL 的 CROSS JOIN。
R
| A | B | C |
|---|---|---|
| 1 | 2 | 4 |
| 3 | 4 | 5 |
| 4 | 5 | 9 |
S
| A | B | C |
|---|---|---|
| 5 | 3 | 3 |
| 4 | 6 | 1 |
(R × S)
| R.A | R.B | R.C | S.A | S.B | S.C |
|---|---|---|---|---|---|
| 1 | 2 | 4 | 5 | 3 | 3 |
| 1 | 2 | 4 | 4 | 6 | 1 |
| 3 | 4 | 5 | 5 | 3 | 3 |
| 3 | 4 | 5 | 4 | 6 | 1 |
| 4 | 5 | 9 | 5 | 3 | 3 |
| 4 | 5 | 9 | 4 | 6 | 1 |
选择(𝜎)
相当于 SQL 的 WHERE。
| 𝜎₁﹤₆ | 第1列值小于第6列值,列从1开始 | 结果集中第1个分量小于第6个分量 |
| 𝜎SAL﹤5000 | 字段SAL值 < 5000 |
- |
投影(𝜋)
相当于 SQL 的 SELECT。
𝜋₃‚₄‚₅ = 投影第3、4、5列
𝜋SAL = 仅投影 SAL 字段
连接
自然连接(⋈)
比较的分量必须是相同的属性组,并且在结果集中将重复的列去掉。
R
| A | B | C |
|---|---|---|
| a | b | c |
| b | a | d |
| c | d | e |
| d | f | g |
S
| A | C | D |
|---|---|---|
| a | c | d |
| d | f | g |
| b | d | g |
R
| A | B | C |
|---|---|---|
| a | b | c |
| b | a | d |
| c | d | e |
| d | f | g |
S
| A | C | D |
|---|---|---|
| a | c | d |
| d | f | g |
| b | d | g |
相同的列 (A,C) 对等检查,发现 R,S 只有 (a,c),(b,d) 相等的。则抽出来,列合并。
结果
| A | B | C | D |
|---|---|---|---|
| a | b | c | d |
| b | a | d | g |
图
有向图无向图
无向图: 节点和线连起来的图
有向图: 有箭头指向节点的图

连通图

V2 不能通过有向连线到达 V3,但是可以通过 V1 再去 V3,所以 V2、V3 连通
强连通
每个节点互相都有路径连通,包括间接连通,那么就能构成强连通。
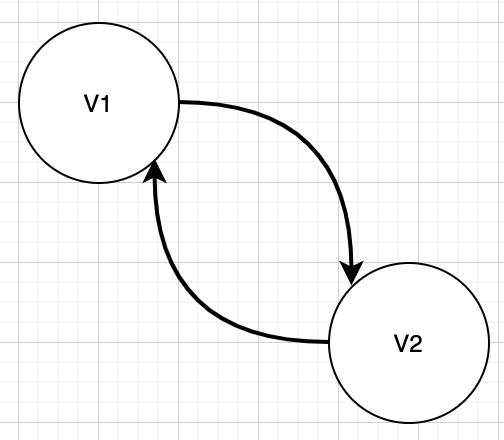
2条边就可以构成强连通
上图任意节点都可以互相直接或间接连通
生成树
在生成树中
边的数量 = 顶点数 - 1
数据结构
队列、栈
队列: 先入先出
栈: 后入先出
广义表
广义表即是列表(表)。
A=()
B=(e)
C=(a,(b,c,d))
D=(A,B,C)=((),(e),(a,(b,c,d)))
E=((a,(a,b),((a,b),c)))
- A 是空表
- B 长度为 1,含有单个原子 e
- C 长度为 2,有一个原子 a,一个子表,子表长度为 3
- D 长度为 3,D 中所有的元素都是表
- E 长度为 1,D 中的元素是一个表,子表长度为 3,子表第3个元素又是一个表
二叉树
度: 某个节点的子节点数量。
完全二叉树
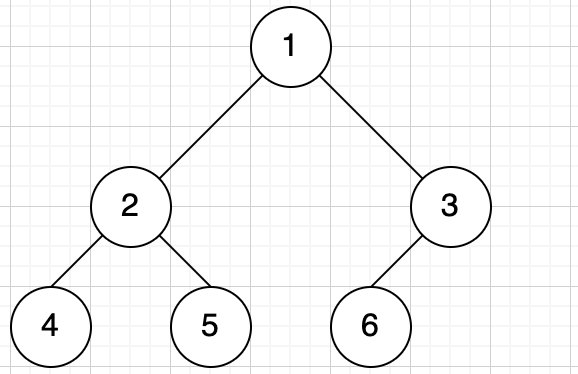
最后一层节点连续集中最左边,为完全二叉树
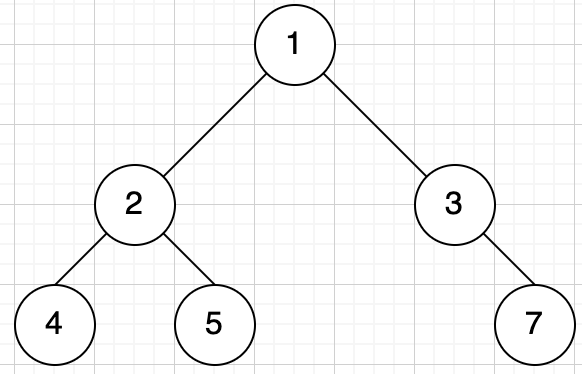
非完全二叉树
设二叉树高度为 h,完全二叉树的 1 ~ h-1 层为满二叉树,最后一层节点连续集中在最左边。
设完全二叉树高度(深度)为 h,节点数为 n
h = ⌊log₂ⁿ⌋ + 1
(⌊⌋ = 取整符号)
满二叉树
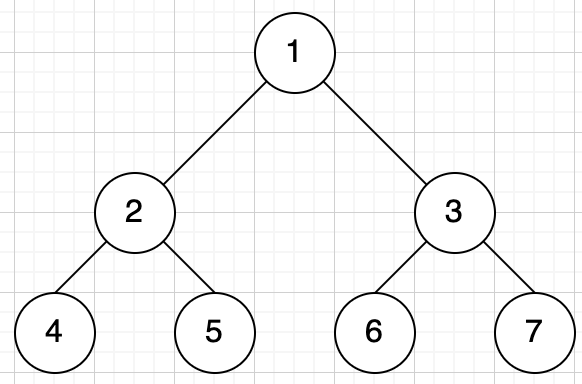
满二叉树
特点: 要么没有叶子节点,要么有2个叶子节点。
设满二叉树高度(深度)为 h,节点数为 n
n = 2ʰ - 1
最优二叉树(哈夫曼树)
哈夫曼树是从根节点出发,到每个带权节点的路径总和最短的树。
哈夫曼树只有度为 2 和 0 的节点(要么没有叶子节点,要么有2个叶子节点)。
用 n 个权值构造最优二叉树,则
哈夫曼树节点数 = 2n - 1
二叉排序树
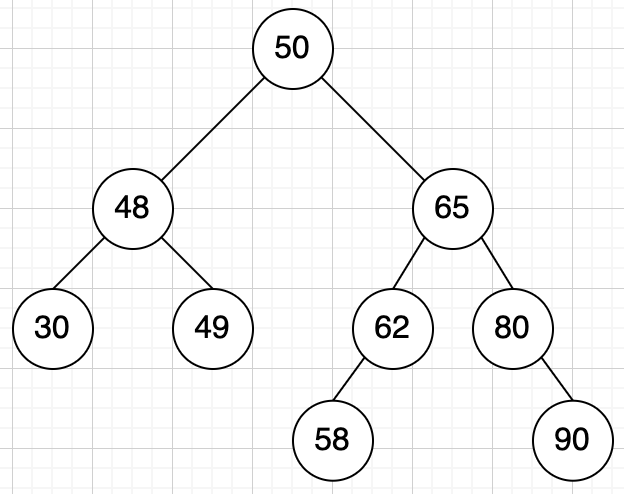
二叉排序树
特点:
- 若左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值
- 若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值
- 左、右子树也分别为二叉排序树
二叉树遍历
| 前序遍历 | 前根遍历 | 根——>左——>右 |
| 中序遍历 | 中根遍历 | 左——>根——>右 |
| 后序遍历 | 后根遍历 | 左——>右——>根 |
已知前序和中序,可以推出后序
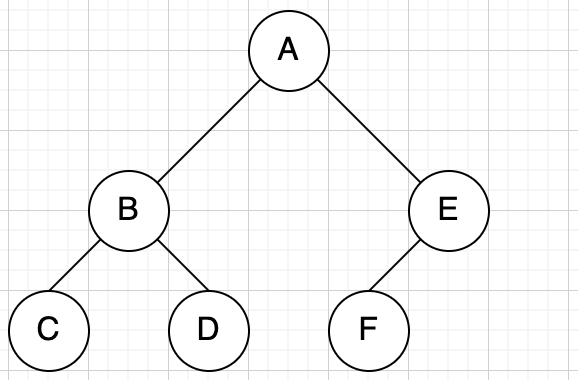
- 前序遍历 = 根左右 = ABCDEF
- 中序遍历 = 左根右 = CBDAFE
- 后序遍历 = 左右根 = CDBFEA
其他树的遍历
| DFS深度优先遍历 | 从根出发从左到右,纵向遍历,直到叶子节点 |
| BFS广度优先遍历 | 从根出发从左到右,横向遍历 |
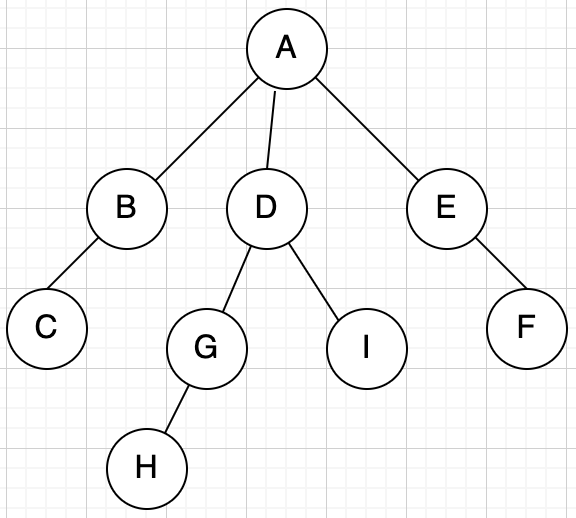
- DFS深度优先遍历 =
ABCDGHIEF - BFS广度优先遍历 =
ABDECGIFH
算法
算法设计
回溯法
策略: 走不通就退回再走
按选优条件向前搜索,如果选到一步发现不优或达不到目标,则退回去重新选择。
贪心法
对问题求解时,总是做出当前看来是最好的选择,找出局部最优解。
分治法
将一个大问题直接分解成小问题,每个小问题都是独立的,然后逐个击破。
动态规划
类似于分治法,但每个小问题的解不是独立的。
如果有很多个相同的小问题,分治法会重复计算,浪费时间。
动态规划的小问题有很多可行解,每个解对应一个值,我们希望找到具有最优值的解。
UML
用例图
| 名称 | 描述 | 图例 |
|---|---|---|
| 参与者 | 小人 |

|
| 用例 | 椭圆,描述一个事务 |
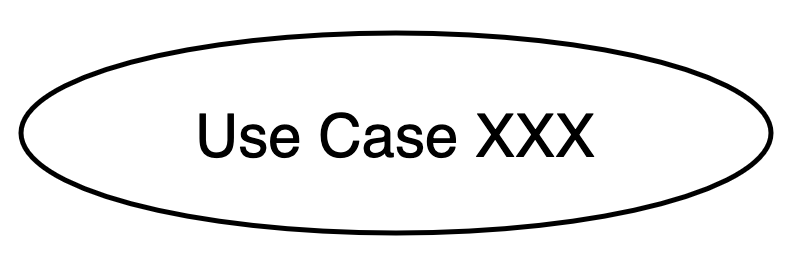
|
| 系统边界 | 矩形,区分多个系统 |
|
| 关系 | 描述 |
|---|---|

包含关系 |
子节点必须执行 父节点->子节点 |
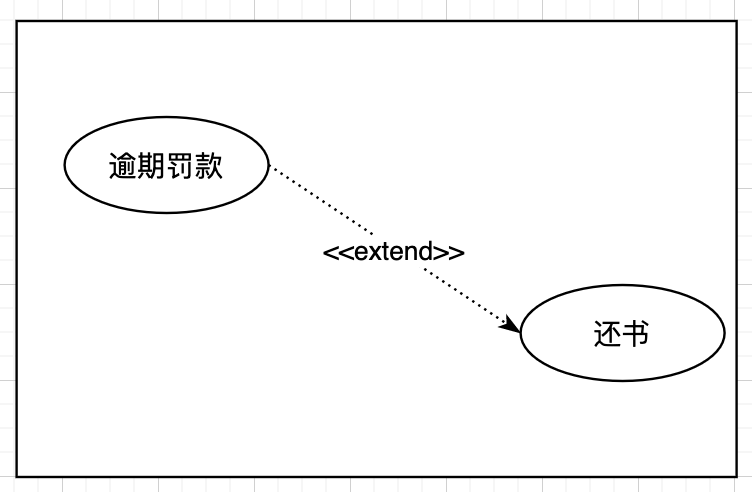
扩展关系 |
可选执行 子节点->父节点 |
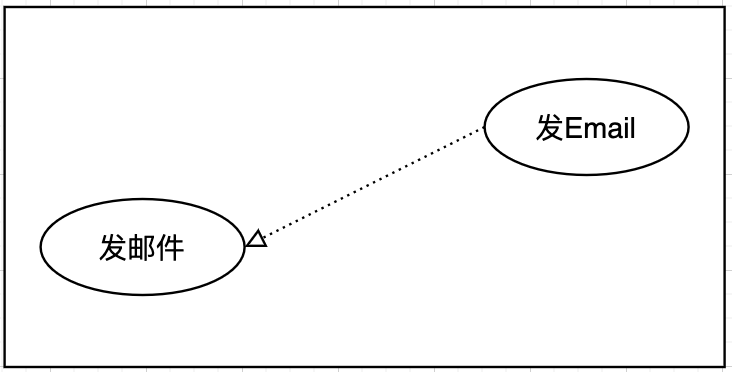
泛化关系 |
继承父节点用例 子节点->父节点 |
附录与引用
[CSDN] IEEE754浮点数表示,为什么偏移码是127?为什么偏移码范围是1~254?
[cnblogs] 软件设计师重点难点—磁盘格式化容量,非格式化容量,数据传输率计算
[cnblogs] SQL 等值连接(内连接)、自然连接(Out join,Left join,Right join)的区别